Putting the “Heterogeneous” in the HSA Foundation
by On Dec 10, 2012
In this month’s article I will introduce the HSA Solution Stack and give a longer-term vision of how HSA can scale beyond CPU-GPU computing. (Hint: The hardware/SoC interconnect fabric is a critical ingredient in this!)
How heterogeneous programming is done today
In its initial stages, HSA addresses the need for easy software programming of GPUs to take advantage of their unique capability to crunch parallel workloads much more efficiently than x86 or ARM CPUs. The graphic above summarizes this concept.
Today, CPUs and GPUs do not share a common view of system memory, requiring an application to explicitly copy data between the two devices. In addition, an application running on the CPU that wants to add work to the GPU’s queue must execute system calls that communicate through the CPU OS’s device driver stack, and then communicate with a separate scheduler that manages the GPU’s work. This adds significant runtime latency, in addition to being very difficult to program.
HSAIL: Heterogeneous programming the HSA way
To avoid this situation and enable easier programming, HSA will allow developers to program at a higher abstraction level using mainstream programming languages, with the addition of libraries targeting HSA. The following is a high-level view of the HSA Solution Stack:
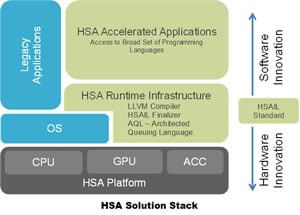 The key to enabling one language for heterogeneous core programming is to have an intermediate runtime layer that abstracts hardware specifics away from the developer, leaving the hardware-specific coding to be done once by the hardware vendor or IP provider. In HSA, the top of this intermediate layer is the HSA Intermediate Language or “HSAIL”.
The key to enabling one language for heterogeneous core programming is to have an intermediate runtime layer that abstracts hardware specifics away from the developer, leaving the hardware-specific coding to be done once by the hardware vendor or IP provider. In HSA, the top of this intermediate layer is the HSA Intermediate Language or “HSAIL”.
The diagram below shows the HSAIL and its path through the HSA runtime stack:
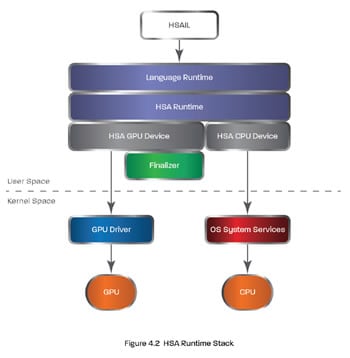 HSAIL is created by compiling a high-level language like C++ with the HSA compilation stack. HSA’s compilation stack is based on the LLVM infrastructure (http://www.llvm.org), which is also used in OpenCL (http://www.khronos.org/opencl/).
HSAIL is created by compiling a high-level language like C++ with the HSA compilation stack. HSA’s compilation stack is based on the LLVM infrastructure (http://www.llvm.org), which is also used in OpenCL (http://www.khronos.org/opencl/).
Creation of HSAIL can occur prior to runtime or during runtime: The OpenCL Runtime includes the compiler stack and is called at runtime to execute a program that is already in data-parallel form. Alternatively, Microsoft’s C++ AMP (C++ Accelerated Massive Parallelism) uses the compiler stack during program compilation rather than execution. The C++ AMP compiler extracts data-parallel code sections and runs them through the HSA compiler stack, and passes non-parallel code through the normal compilation path.
The diagram below shows the HSA Compilation Stack, where programming code is compiled into HSAIL using the LLVM compilation infrastructure:
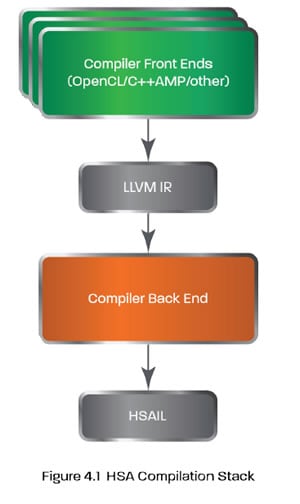
The hardware-specific HSA Finalizer
A key role is played by the hardware-specific “finalizer” which converts HSAIL to the computing unit’s native instruction set. Hardware and IP vendors are responsible for creating finalizers that support their hardware. The finalizer is lightweight and can be run at compile time, installation time or run time depending on requirements.
The finalizer is the point at which the specifics of different heterogeneous computing units are addressed. Initial HSA implementations will most likely support GPU compute with finalizers from GPU vendor HSA members like AMD, Imagination and ARM. (And maybe even Qualcomm to support their Adreno graphics cores.)
Heterogeneous: More than CPU and GPU
However, as discussed in last month’s article, many existing heterogeneous architectures have additional discrete processing units for functions like audio (digital signal processing or stream processing), image and video processing (SIMD frame processing), and security. As HSA matures, hardware and IP vendors creating these processing units may want to enable HSA programmability on their hardware by creating hardware-specific finalizers.
From dumb scheduling to smart scheduling
Having multiple heterogeneous processing units will complicate workload scheduling from a system perspective. The harsh reality is that existing workload scheduling and OS scheduling algorithms are relatively simple and generally only take into account local activity on a processing unit or cluster of homogeneous processing units (see the Linux Completely Fair Scheduler for one example of how scheduling is implemented: http://en.wikipedia.org/wiki/Completely_Fair_Scheduler).
These algorithms do not take into account the existing traffic coursing throughout the system or a view into other processing units. This lack of a global view for scheduling virtually guarantees there will be contention and stalling as processing units wait for access to precious system resources, especially the DRAM.
One way to enhance workload scheduling will be to probe existing runtime data flows at critical points throughout a system’s SoC interconnect fabric, and use this information to assign priorities to workloads, and workloads to processing units. As heterogeneous processing becomes the norm and more processing units are added to a system, this type of interconnect-assisted scheduling will be required.
In other words, the hardware interconnect is a key enabler to putting the heterogeneous into HSA.
Sources
Kyriazis, George (AMD). “Heterogeneous System Architecture: A Technical Review.” Whitepaper, HSA Foundation, August 2012.
HSA Solution Stack diagram is from http://developer.amd.com/Resources/hc/heterogeneous-systems-architecture/Pages/default.aspx.