FlexNoC 5 XL Option
Enhanced Scalability and Flexibility to Support AI and ML Chip Designs
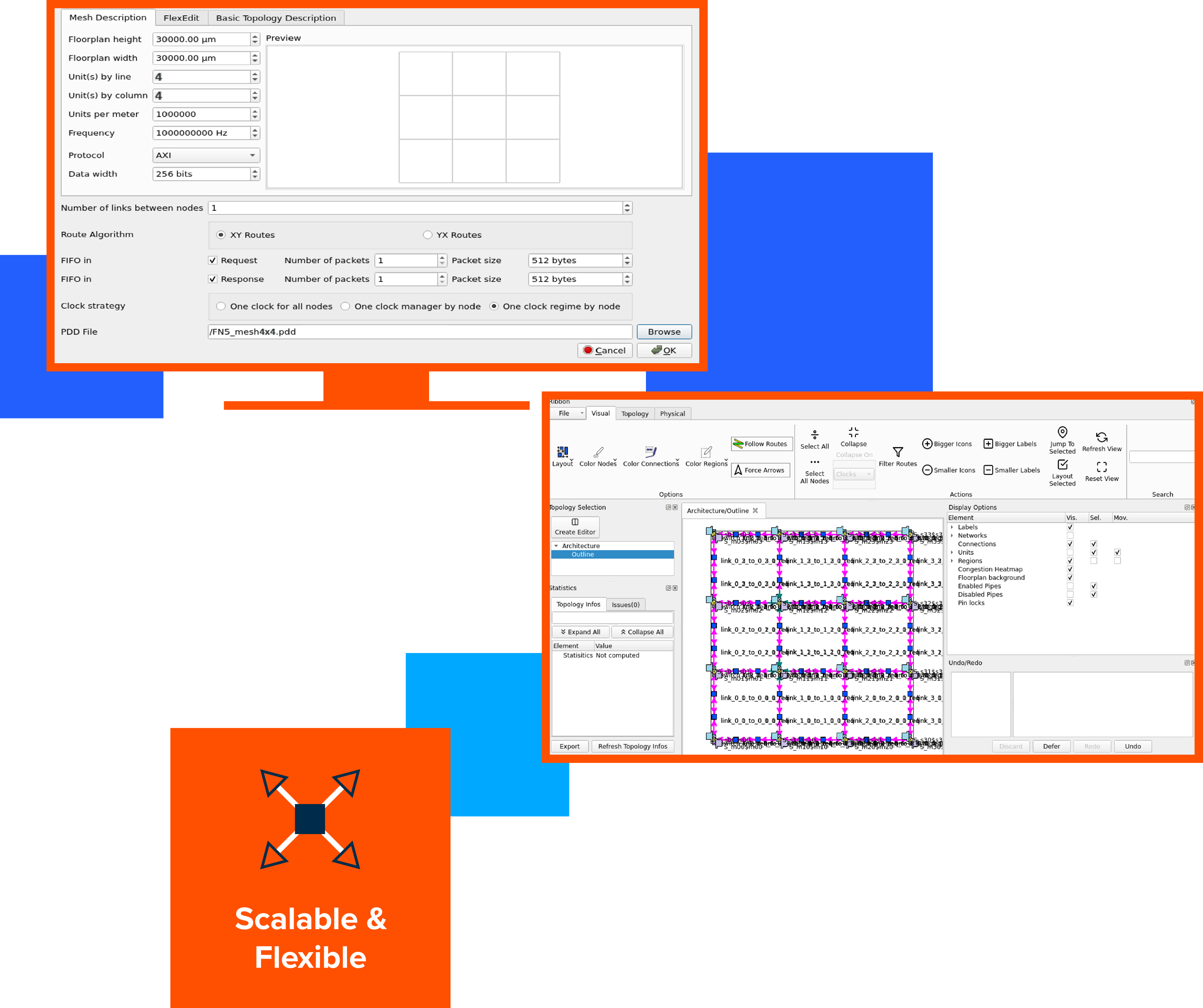
Automates Topology Creation for Advanced AI, DNN and ML Systems, Enhancing Scalability and Flexibility
Generating mesh, ring, and torus topologies for AI, DNN, and ML designs poses challenges in scalability, latency, fault tolerance, and data communication efficiency.
The XL Option automatically generates these interconnect topologies. Unlike black box compiler approaches, SoC architects can edit generated topologies and optimize each individual network router.
Additionally, it also expands the number of NoC initiators and targets, allowing for the integration of a larger number of IP blocks and components within the system ensuring seamless integration of diverse functionalities.

FlexNoC XL Option
Enables designers to handle higher data volumes and optimize system performance
Flexible Topologies
Create highly scalable Ring, Mesh and Torus topologies.
Small to Large SoCs
Efficiently span long distances across huge chips.
Higher Bandwidth
Increase on-chip and off-chip bandwidth.
XL Option Key Features
- Mesh-based interconnect generation
- Expanded number of NoC initiators and targets
- Broadcast links, virtual channels and and source-synchronous communications.
- Support of data widths up to 1024 bits
- High Bandwidth Memory (HBM) support such as HBM2/HBM2E/HBM3
- Multichannel memory support
XL Option Product Benefits
Advanced Scalability and Flexibility
Via mesh-based interconnect generation.
Seamless Integration of IP Blocks and Components
Leads to optimized system functionality.
Enhanced Communication Efficiency
Improves overall system performance and ensures smooth operation even in highly interconnected designs.
Increased Data Widths for Higher Data Volumes
Improves system performance and accelerating data-intensive computations.
High Bandwidth Memory (e.g. HBM2/HBM2E/HBM3)
Enhances the system’s ability to handle large amounts of data, leading to improved performance.
Read more about why we are unique on our NoC Technology page.